










Adobe’s new AI-based foundation model, Firefly Image 3, is now in beta. Available in Photoshop…







Adobe’s new AI-based foundation model, Firefly Image 3, is now in beta. Available in Photoshop…

Enlarge (credit: Getty) Reddit has made it clear that it’s an ad-first business. Today, it…

The Polestar Phone. Someday it will unlock your Polestar car. [credit: Polestar ] Polestar, the…

Following the disappointment of the Humane Ai Pin, the Rabbit R1 aims to offer something…
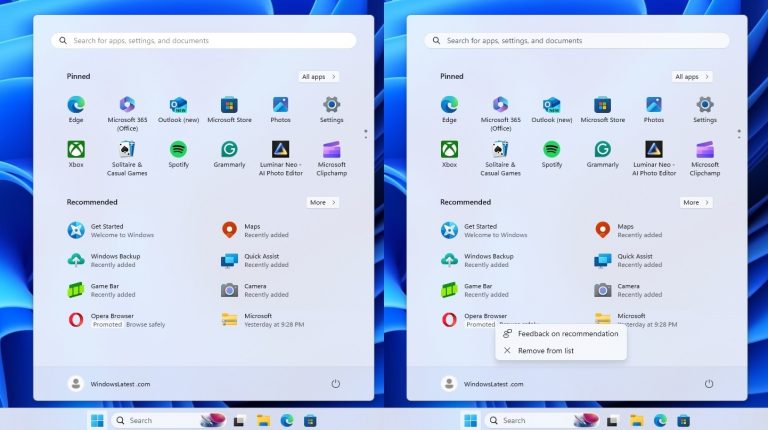
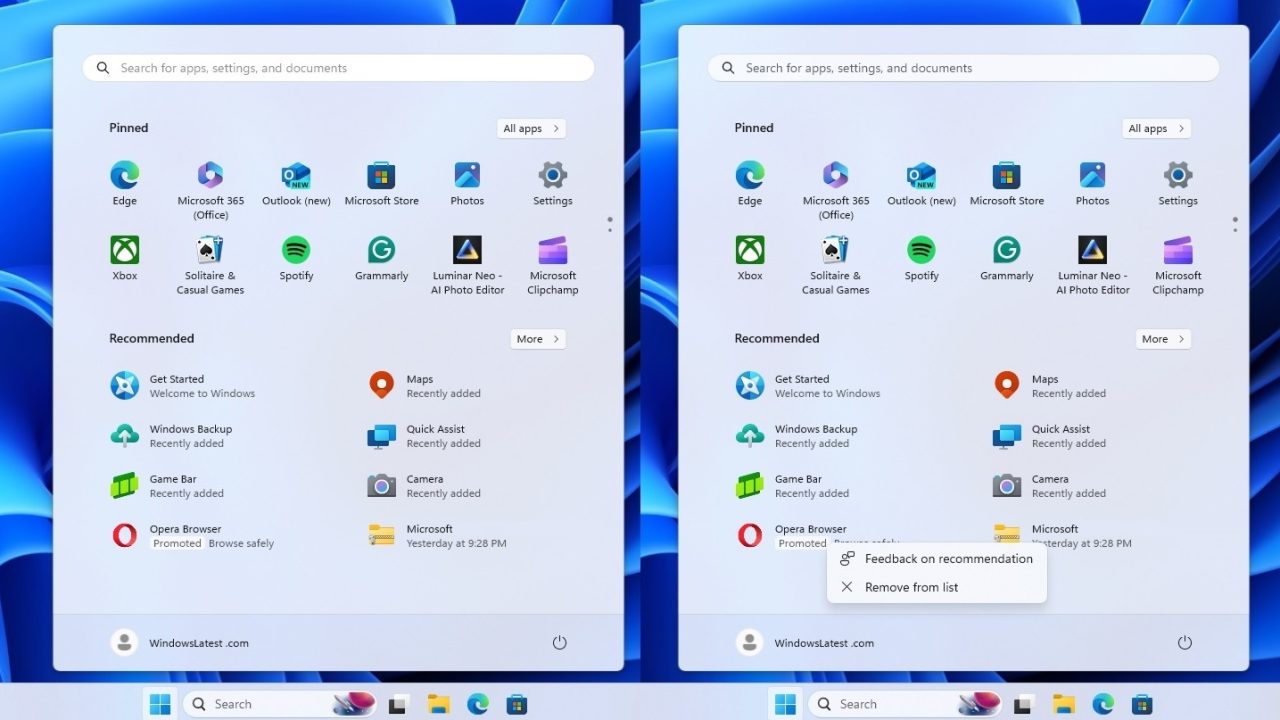
Windows doesn’t make a lot of money, and due to competition laws, Microsoft cannot divert…

Enlarge / M82, the site of what’s likely to be a giant flare from a…

Enlarge (credit: Getty Images) Hackers backed by a powerful nation-state have been exploiting two zero-day…

Micro-LEDs are in line to replace OLEDs but need another half decade or so of…

Enlarge (credit: Getty Images) On Friday, a federal judicial panel convened in Washington, DC, to…

Phase change memory, or PCM for short, works by shifting between two physical states: crystallized…

(credit: Getty Images | eccolo74) The US Chamber of Commerce and other business groups sued…

The joint press release issued Monday by the Premier League and Alliance for Creativity and…
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |